Learning Errors
I finally had the chance to give the ImageNet winners a read-through. It’s Microsofts Deep Residual Learning technique that allowed them to learn a convnet of 150 layers. Sure, Google matched them in classification error but their localization error blew everyone else out of the water. The idea behind their technique was that each layer learns the residuals instead of an entire mapping function. That is, each layer of the network adds on to the previous layer instead of finding a complete mapping function. It’s kind of intuitively obvious that this is a better way to learn deep networks than trying to do the entire thing in one shot now that you think about it.
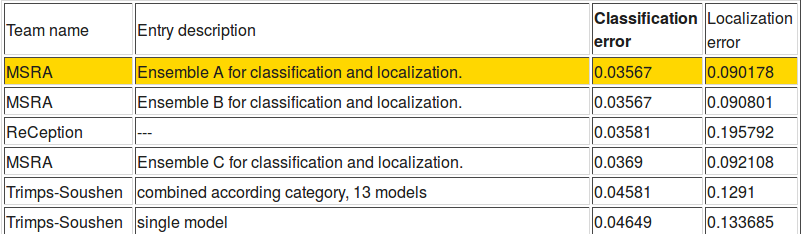 Here’s the same picture from the last post
Here’s the same picture from the last post
Then you think about it a little harder and realize this trend might be going somewhere. The paper that inspired them is the Highway Networks paper, except Highway Networks implement a more complex technique where you learn how much of the previous layer to pass through. In Residual Learning, the entire previous layer is used completely.
The other place where this worked wonderfully is Deep Adversarial Network paper for generating natural images. It actually gives extremely realistic generated images, and works by starting with a small image and iteratively enlargening it and generating the residuals. The training data is simply the reverse process, where you iteratively make smaller the size of the image and feed the network the information lost during scaling.
This is not a new technique by far, remember AdaBoost and gradient boosting? Something something using a bunch of weak learners and working with only the errors of the previous learner at each iteration?
My long stretch observation is that if you squint your eyes hard enough at Batch Normalization, it kind of looks like it’s predicting the errors of a Taylor Expansion at each time step. A Taylor polynomiala kind of looks like
where you could linearize the residuals by doing
and if you squint really hard it kind of looks like what Batch Normalization is doing. Maybe something more to look at would be to force a network structure that actually does this explicitly.
Residual learning seems like a really good direction to pursue deep learning models; I bet there will be a few more models that look into this topic.