NIPS 2015: Through the Looking Glass
NIPS being the first conference I’ve been to was somewhat of a information overload. That said, it was probably one of the most educational weeks I’ve had, catching up on the state of the art in deep learning, admiring how pretty Bayesian techniques are and simultaneously how they’re never used for one reason or another. Montreal probably had the best weather ever for this time of the year – it was so warm that I passed with a light jacket and flip flops during the middle of the conference. But enough said, let’s talk about NIPS 2015.
Some warning: My expertise is mostly in deep learning. Some of the impressions I got of other subjects may be wildly incorrect.
Tutorials
Overall the tutorials were well advertised, just an introduction to topics at hand. Jeff Dean and Oriol Vinyals talked about Tensorflow. Tensorflow pretty much follows in the footsteps of Theano, creating computational graphs that you can compile and run on the GPU. The upside is that it has millions of dollars thrown at it, so it’s almost definitely going to be better supported. Though a couple people tested Tensorflow and found it slow at first, it’s definitely getting faster and better. At the same time, Jeff announced the state-of-the-art on ImageNet with a different inception architecture, dubbed ReCeption, halving the error from last year. It was a big deal until ImageNet announced results a couple days later and Microsoft beat them in both classification and localization error.
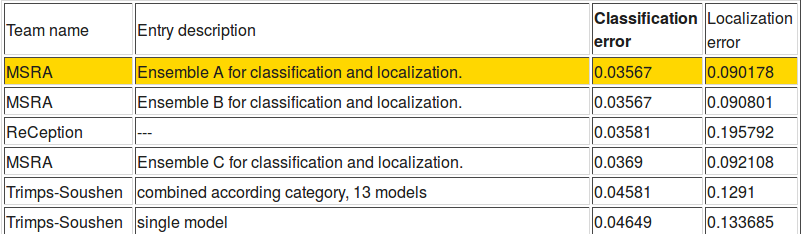 Sorry Google!
Sorry Google!
The other two tutorials were very good introductions, and set the stage for the rest of the conference. Bayesian methods seem to have discovered their backprop algorithm in variational inference and MCMC methods. My take away is that Bayesian scientists think of a model, then throw variational inference and MCMC at the model until they get results. You get uncertainties, something most other learning algorithms can’t handle, but none of it scales very well.
Reinforcement learning is all the rage after DeepMinds deep Q-learning paper came out, and there’s a bunch of work on learning Q functions and getting robots to hang coat hangers and pull out nails. The interesting thing is that there seem to be very few papers at NIPS dedicated to RL. However, the tutorial and workshop on Deep RL were both presented very good work. The work seen at NIPS were all conglomerations of research papers and not any particular one.
On to the papers!
Deep Learning
The big takeaway is that Deep Learning models are getting more and more complex. Instead of working on the layer level, we’re already reaching the module level where we pick out modules that do certain things and stick them together to test. In a way, it more resembles a weird combination between software design and machine learning. Still, tons of work into interesting modules and novel applications.
Tools of the trade
Basically a bunch of techniques that your deep learning model should probably be using if the problem is at all complicated. Batch Normalization reduces the training speed by an order of magnitude on ImageNet, and is an easy drop-in for any model. Spatial Transformer Networks look really cool, where you regress a transformation before running it through the actual network. This looks very useful as a targetting mechanism for a specific section of an image and gets good results on your favorite handwritten digits dataset.
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Attention based models partially solves the problem of memory. The idea is that sequences get an attention module that looks at parts of an image or text. Soft attention is generally the way to go where the final result from the looking at the image/text is a weighted sum where the weights are assigned by the attention module. Attention has become one of those typical modules that you have to think about when designing a Deep Learning system.
Attention-Based Models for Speech Recognition
Learning Wake-Sleep Recurrent Attention Models
Memory
Memory was one of the hottest topics NIPS 2015, with an entire overflowing (I was standing for most of it) workshop dedicated to it. Despite the major work, there’s still a lot more to be done. Most of the models were well received still lack a useful write-unit. I’m looking at you, Memory Networks. When problems become too large for memory, there’s no way for the network to learn to do memory management.
The two stack based networks only allow one computation per time-step, which means they do not really simulate a turing complete memory. Turing machines that use two stacks only work because you can “turn” the second stack upside down on the first and imagine that the point where they meet is the head of the Turing machine. However, without multiple push-pops on every input, the Turing machine is unable to seek, making anything more complex than counting impossible.
The remaining class of algorithms seem to have all required attributes, but are slow and complex. Experiments for both Neural Turing Machines and Dynamic Memory Networks are restricted to toy problems. I suspect that they will be too slow and hard to train on real scale problems in their current form.
Learning to Transduce with Unbounded Memory
Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets
Dynamic Memory Networks for Natural Language Processing
Applications
Computer Vision has turned into applied convnets and most speech related problems have turned into applied LSTMs (with attention). That said, there’s still lots of interesting work like generating images almost completely from scratch and teaching a computer to read. What I also took away were some really big QA datasets for testing algorithms, especially memory based ones that we’re definitely going to see in the upcoming year.
- Baidu released an image question-answering dataset with over 300k image-question-answer triplets.
- DeepMind released a QA dataset based off of a paragraph of context, where the entities are all scrambled up so you can’t just look on Wikipedia.
- Facebook’s QA dataset has been here forever but I still think it’s a good one to mention.
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Teaching Machines to Read and Comprehend
Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering
Deeper and Deeper
2 papers have stood out in training deeper and deeper networks. HF learning for RNNs trains a 15 layer network, whereas Highway Nets get to over a hundred. The Highway Network even learns to not use later layers, meaning it almost automatically gives some capacity control
Hessian-free Optimization for Learning Deep Multidimensional Recurrent Neural Networks
Training Very Deep Networks (Highway Networks)
Misc
Spectral pooling is an amazing idea, lowpass filtering the images instead of doing maxpooling. Even better when you consider that convolutions in frequency space is just multiplications, dropping a log N term from the complexity of our networks. However, the authors here don’t actually do the whole thing in frequency space, they focus on how the parameterization helps gradient descent be smoother. It’ll be interesting to see an entire network in frequency space, and maybe we go a step further and do it in some kind of wavelet space.
Spectral Representations for Convolutional Neural Networks
Super interesting “application” of a neural net by encoding discrete optimization problems and making the network learn to solve it. It works by a simple modification of the attention based model. I’m interested in seeing where further work in approximating NP-hard optimization problems with Deep Learning goes…
Machine learning scientists are already trying to run themselves out of a job, we haven’t even invented strong AI yet!
Efficient and Robust Automated Machine Learning
Ladder Networks are a very elegant way to do semi-supervised learning when you don’t have a lot of labels for your data. They just learn an autoencoder along with the classifier, where most of the layers are shared.
Semi-Supervised Learning with Ladder Networks
Binary weights get pretty close to the state-of-the-art compared to real numbers? It’s very surprising how little precision you need to get amaing results.
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
Learning lanugages models efficiently, because nobody has time for you to backprop through the 20k elements in your vocabulary.
Efficient Exact Gradient Update for training Deep Networks with Very Large Sparse Targets
Reinforcement Learning and Control
I didn’t put a lot of references because most of the deep reinforcement learning topics were actually published in previous conferences. However, RL is very much the vogue based on the tutorials and workshops that gave us great introductions to this topic. All of Deep RL is basically sprung from the DeepMind Atari paper. The policy learning could very well be another angle to tackle the long term dependency and memory problem that we have right now. It doesn’t hurt that reinforcement learning sessions always shows you some very interesting videos.
Interactive Control of Diverse Complex Characters with Neural Networks
Action-Conditional Video Prediction using Deep Networks in Atari Games
Learning Deep Neural Network Policies with Continuous Memory States
Bayesian
Lots of the papers in this topic are papers that I’d like to know more about but don’t. Again, it looks like a lot of Bayesian learning is tending towards the *throw variational inference and MCMC* at problems type paper, so you’ll undoubtably see a lot of that. However, the issues with this is that Variantion Inference and MCMC techniques are notoriously slow, and so there’s another bundle of papers that discuss how to make these sampling based approaches faster. It seems to me that Gaussian Processes are very good at solving small scale problems with not many data points right now, but neural networks still scale harder. I’m hoping to see a lot more study into GPs in the future, either in Bayesian Optimization or somehow else integrated into deep networks.
Fast Second Order Stochastic Backpropagation for Variational Inference
Scalable Inference for Gaussian Process Models with Black-Box Likelihoods
Learning Stationary Time Series using Gaussian Processes with Nonparametric Kernels
Gaussian Process Random Fields
There was also an entire session that I missed on probabilistic programming. Again, tons of using Variational Inference to approximate your posterior and throwing it at problems until they stop being problems. It will be interesting to see if it can be sped up even more.
Automatic Variational Inference in Stan
Misc
Another GP based technique that extends line searches to stochastic optimization. Looks like another very good drop-in replacement optimizer for our backpropagating needs.
Probabilistic Line Searches for Stochastic Optimization
There was a lot of analysis on asyncronous SGD type algorithms, a big reason is that all the big companies are requiring a couple thousand machines to perform optimization on huge models. Most of them just established bounds and guarantees. The takeaway message is that in the long run, async SGD is no different from normal SGD.
Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization
Taming the Wild: A Unified Analysis of Hogwild!-Style Algorithms
Asynchronous stochastic convex optimization: the noise is in the noise and SGD don’t care
Conclusion
Overall the conference was a huge information overload. The takeaways for me are that:
- Memory is the next big thing we’re gonna have to invent. Some kind of framework that makes storing information and training models to read/write this information easy will be essential next steps.
- Reinforcement learning is pretty hip right now. I expect to see it on more and more robots in the next couple years. If the DARPA robotics challenge were held two years from now we would see far fewer falling robots.
- Computer Vision and NLP have been unified under Applied Deep Learning. Robotics and planning AIs are slowly heading towards this as well.
- Gaussian processes are really cool. You literally decide on a single parameter (the covariance function) and tell your model to go learn things.