Dec 26, 2015
I finally had the chance to give the ImageNet winners a read-through. It’s
Microsofts Deep Residual Learning technique that allowed them to learn
a convnet of 150 layers. Sure,
Google matched them in classification error but their localization error
blew everyone else out of the water. The idea behind their technique was that
each layer learns the residuals instead of an entire mapping function.
That is, each layer of the network adds on to the previous layer instead
of finding a complete mapping function. It’s kind of intuitively obvious
that this is a better way to learn deep networks than trying to do the entire
thing in one shot now that you think about it.
Read more
Dec 23, 2015
NIPS being the first conference I’ve been to was somewhat of a information
overload. That said, it was probably one of the most educational weeks I’ve
had, catching up on the state of the art in deep learning, admiring how pretty
Bayesian techniques are and simultaneously how they’re never used for one reason
or another. Montreal probably had the best weather ever for this time of the year
– it was so warm that I passed with a light jacket and flip flops during the
middle of the conference. But enough said, let’s talk about NIPS 2015.
Some warning: My expertise is mostly in deep learning. Some of the impressions I got
of other subjects may be wildly incorrect.
Tutorials
Overall the tutorials were well advertised, just an introduction to topics at hand.
Jeff Dean and Oriol Vinyals talked about Tensorflow. Tensorflow pretty much
follows in the footsteps of Theano, creating computational graphs that you can
compile and run on the GPU. The upside is that it has millions of dollars thrown
at it, so it’s almost definitely going to be better supported. Though a couple people
tested Tensorflow and found it slow at first, it’s definitely getting faster
and better. At the same time, Jeff announced the state-of-the-art on ImageNet
with a different inception architecture, dubbed ReCeption, halving the error
from last year. It was a big deal until ImageNet announced results a couple
days later and Microsoft beat them in both classification and localization error.
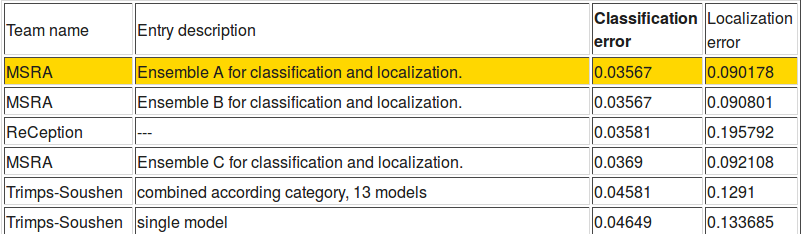 Sorry Google!
Sorry Google!
Read more